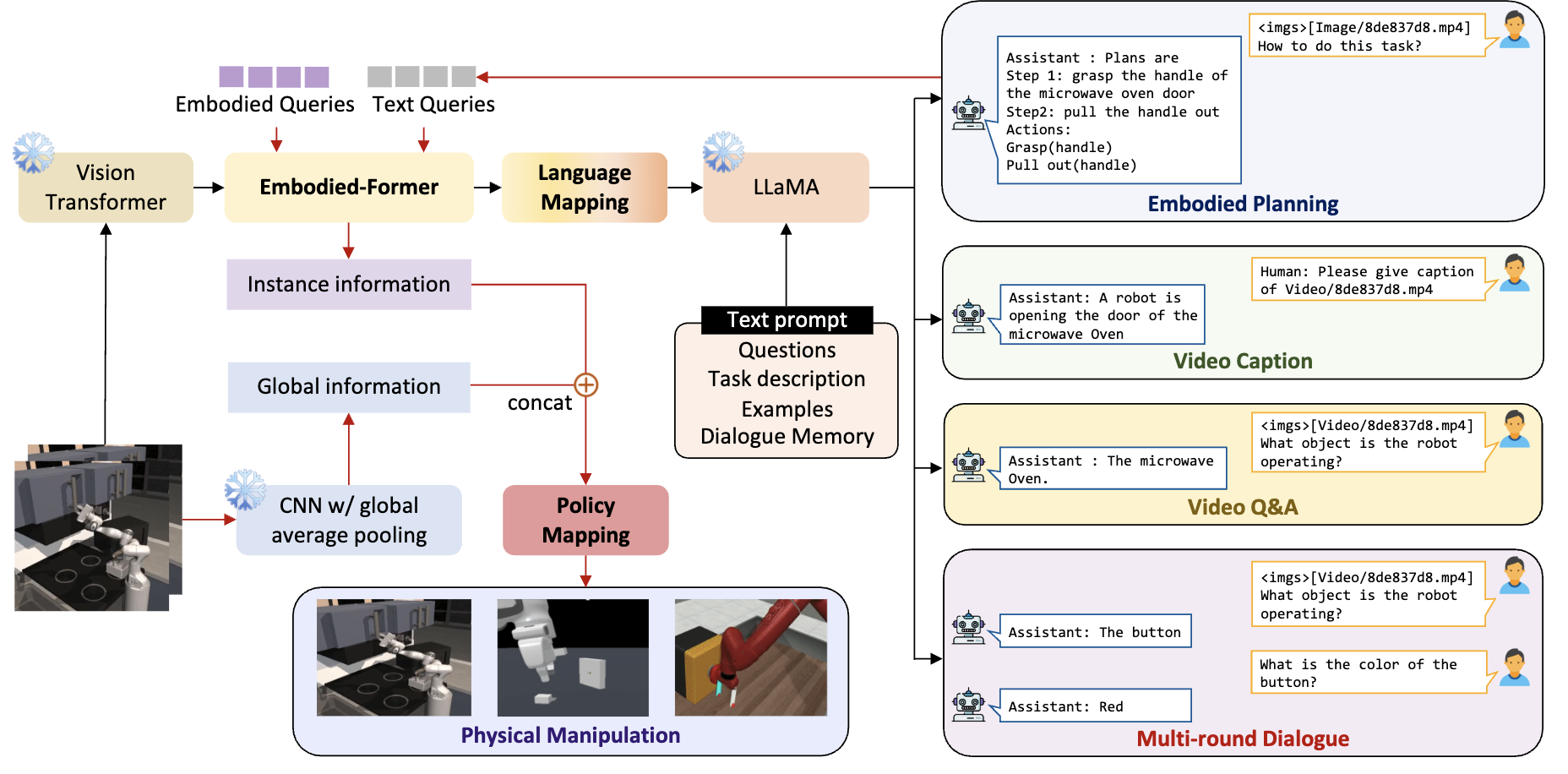
Embodied AI represents a critical frontier in robotics, where the capacity to devise coherent action sequences for robots to accomplish specific tasks in physical environments is both essential and fraught with inherent challenges. Recently, there has been an increasing interest in developing large foundation models capable of generating embodied plans by processing natural language instructions and environmental observations. In this paper, we introduce EmbodiedGPT, a large-scale end-to-end multi-model foundation model for embodied AI.
Our contributions can be categorized into three folds: First, we meticulously craft a large-scale embodied planning dataset, encompassing extensive videos and planning instructions derived from the Ego4D dataset, with scrupulous prompt design and quality assurance. Second, we advocate a cost-effective training method for end-to-end multimodal large models, generating a sequence of sub-goals in planning pursuant to observations by harnessing the potency of the “Chain of Thought.” Specifically, we augment the 7B language model’s capacity to produce high-quality planning by employing prefix adapters to train it on the EgoCOT dataset, circumventing overly divergent language model responses.
Lastly, we introduce a paradigm for extracting task-related features from LLM-generated planning queries, forming a closed loop between high-level planning and low-level control. Our comprehensive experiments substantiate that our model effectively bolsters the performance of embodied tasks, including Embodied Planning, Embodied Control, Visual Captioning, and Visual Q\&A.